im going back to writing code by hand
CROSSPOST FROM blog.k10s.dev
I
Here is k10s: https://github.com/shvbsle/k10s/tree/archive/go-v0.4.0
234 commits. ~30 weekends. Built entirely on vibe-coded sessions with Claude, whenever my tokens lasted long enough to ship something.
I'm archiving my TUI tool and rewriting it from scratch.
k10s started as a GPU-aware Kubernetes dashboard (and my first foray into building something serious with AI). Think k9s but built for the people running NVIDIA clusters, people who actually care about GPU utilization, DCGM metrics, and which nodes are sitting idle burning $32/hr. I built it in Go with Bubble Tea [1] and it worked.
For a while... :(
I learned over these 7 months is worth more than the 1690 lines of model.go I'm throwing away. And I think anyone doing serious vibe-coding can benefit from this, because this part doesn't surface much (I feel it gets buried under the demo reels and the velocity wins).
tl;dr: AI writes features, not architecture. The longer you let it drive without constraints, the worse the wreckage gets. The velocity makes you think you're winning right up until the moment everything collapses simultaneously.
II
vibe coding high
I started k10s in late September 2025. The first few weeks were magic. I'd prompt Claude with "add a pods view with live updates" and boom, it worked. Resource list views, namespace filtering, log streaming, describe panels, keyboard navigation. Each feature landed clean because the project was small enough that the AI could hold the whole thing in context.
The basic k9s clone took maybe 3 weekends. Resource views for pods, nodes, deployments, services. A command palette. Watch-based live updates. Vim keybindings. All working, all vibe-coded in single sessions. I was building at maybe 10x my normal speed and it felt incredible.
Then I wanted the main selling point.
The whole reason k10s exists is the GPU fleet view. A dedicated screen that shows you every node's GPU allocation, utilization from DCGM, temperature, power draw, memory. Not buried in kubectl describe node output, but right there in a purpose-built table with color-coded status. Idle nodes in yellow. Busy in green. Saturated in red.
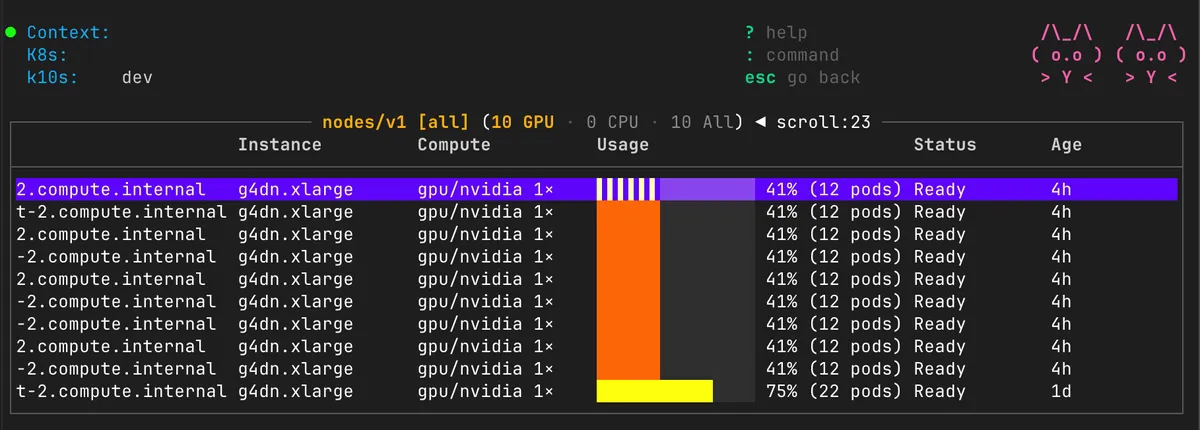
And Claude one-shot it. I prompted for the fleet view, it generated the FleetView struct, the tab filtering (GPU/CPU/All), the custom rendering with allocation bars. It looked beautiful. I was riding the high.
Then I typed :rs pods to switch back to the pods view.
Nothing rendered. The table was empty. Live updates had stopped. I switched to nodes, it showed stale data from the fleet view's filter. I went back to fleet, the tab counts were wrong.
The god object had consumed itself.
This is the title of the blog post. This is where I intervened for the first time. For 7 months I'd been prompting and shipping without ever sitting down and actually reading the code Claude wrote. I'd look at the diff, verify it compiled, test the happy path, move on. But now something was fundamentally broken and I couldn't just prompt my way out of it.
So I sat down and read model.go. All 1690 lines. I was horrified.
Here's what it looked like. One struct to rule them all:
type Model struct {
// 3rd party UI components
table table.Model
paginator paginator.Model
commandInput textinput.Model
help help.Model
// cluster info and state
k8sClient *k8s.Client
currentGVR schema.GroupVersionResource
resourceWatcher watch.Interface
resources []k8s.OrderedResourceFields
listOptions metav1.ListOptions
clusterInfo *k8s.ClusterInfo
logLines []k8s.LogLine
describeContent string
currentNamespace string
navigationHistory *NavigationHistory
logView *LogViewState
describeView *DescribeViewState
viewMode ViewMode
viewWidth int
viewHeight int
err error
pluginRegistry *plugins.Registry
helpModal *HelpModal
describeViewport *DescribeViewport
logViewport *LogViewport
logStreamCancel func()
logLinesChan <-chan k8s.LogLine
horizontalOffset int
mouse *MouseHandler
fleetView *FleetView
creationTimes []time.Time
allResources []k8s.OrderedResourceFields // fleet's unfiltered set
allCreationTimes []time.Time // fleet's timestamps
rawObjects []unstructured.Unstructured
ageColumnIndex int
// ...
}
UI widgets. K8s client. Per-view state for logs, describe, fleet. Navigation history. Caching. Mouse handling. All in one struct. And the Update() method was a 500-line function dispatching on msg.(type) with 110 switch/case branches.
This is the moment I stopped vibe-coding and started thinking.
III
five tenets from the wreckage
Here's what I extracted from 7 months of watching AI generate a codebase that slowly ate itself. Each of these is something I did wrong, why it happens with AI-assisted coding, and what you should actually put in your CLAUDE.md or agents.md to prevent it.
Tenet 1: AI builds features, not architecture.
Every time I prompted Claude for a feature, it delivered. Perfectly. The fleet view worked on the first try. Log streaming worked. Mouse support worked. The problem is that each feature was implemented in the context of "make this work right now" without any awareness of the 49 other features sharing the same state.
Here's what the resourcesLoadedMsg handler looks like. This is the code that runs every time you switch views:
case resourcesLoadedMsg:
m.logLines = nil // Clear log lines when loading resources
m.horizontalOffset = 0 // Reset horizontal scroll on resource change
if m.currentGVR != msg.gvr && m.resourceWatcher != nil {
m.resourceWatcher.Stop()
m.resourceWatcher = nil
}
m.currentGVR = msg.gvr
m.currentNamespace = msg.namespace
m.listOptions = msg.listOptions
m.rawObjects = msg.rawObjects
// For nodes: store the full unfiltered set, classify, then filter
if msg.gvr.Resource == k8s.ResourceNodes && m.fleetView != nil {
m.allResources = msg.resources
m.allCreationTimes = msg.creationTimes
if len(msg.rawObjects) > 0 {
m.fleetView.ClassifyAndCount(m.rawObjectPtrs())
}
m.applyFleetFilter()
} else {
m.resources = msg.resources
m.creationTimes = msg.creationTimes
m.allResources = nil
m.allCreationTimes = nil
}
See the if msg.gvr.Resource == k8s.ResourceNodes && m.fleetView != nil conditional? That's the fleet view being special-cased inside the generic resource loading path. Every new view that needed custom behavior got another branch here. And every branch needed to manually clear the right combination of fields or the previous view's data would bleed through.
How many = nil cleanup lines exist in this file? I counted:
m.logLines = nil // Clear log lines when loading resources
m.allResources = nil // Clear fleet data when not on nodes
m.resources = nil // Clear resources when loading logs
m.resources = nil // Clear resources when loading describe view
m.logLines = nil // Clear log lines when loading describe view
m.resources = nil // Clear resources when loading yaml view
m.logLines = nil // Clear log lines when loading yaml view
m.logLines = nil // ... two more in other handlers
m.logLines = nil
Nine manual nil assignments scattered across a 1690-line file. Miss one and you get ghost data from the previous view. This is what happens when there's no view isolation. AI can't see this pattern decaying over time because each prompt only touches one code path.
What to do instead: Write the architecture yourself before any code. Not a vague design doc. A concrete set of interfaces, message types, and ownership rules. Then put those rules in your CLAUDE.md so the AI sees them on every prompt:
# Architecture Invariants (CLAUDE.md)
- Each view implements the View trait. Views do NOT access other views' state.
- All async data arrives via AppMsg variants. No direct field mutation from background tasks.
- Adding a new view MUST NOT require modifying existing views.
- The App struct is a thin router. It owns navigation and message dispatch. Nothing else.
The AI will follow these if you write them down. It just won't invent them for you.
Tenet 2: The god object is the default AI artifact.
AI gravitates toward single-struct-holds-everything because it satisfies the immediate prompt with minimal ceremony. But it gets worse. Because there's no view isolation, key handling becomes a nightmare. Here's the actual key dispatch for the s key:
case m.config.KeyBind.For(config.ActionToggleAutoScroll, key):
if m.currentGVR.Resource == k8s.ResourceLogs {
m.logView.Autoscroll = !m.logView.Autoscroll
if m.logView.Autoscroll {
m.table.GotoBottom()
}
return m, nil
}
// Shell exec for pods and containers views
if m.currentGVR.Resource == k8s.ResourcePods {
// ... 20 lines to look up selected pod, get name, namespace ...
return m, m.commandWithPreflights(
m.execIntoPod(selectedName, selectedNamespace),
m.requireConnection,
)
}
if m.currentGVR.Resource == k8s.ResourceContainers {
// ... container exec logic ...
return m, m.commandWithPreflights(m.execIntoContainer(), m.requireConnection)
}
return m, nil
One keybinding. Three completely different behaviors depending on which view you're in. The s key means "autoscroll" in logs, "shell" in pods, and "shell into container" in containers. This is all in one flat switch because there are no per-view key maps. The AI generated this because I said "add shell support for pods" and it found the nearest key handler and jammed it in.
And look at how Enter works. This is the drill-down handler:
case m.config.KeyBind.For(config.ActionSubmit, key):
// Special handling for contexts view
if m.currentGVR.Resource == "contexts" {
// ... 12 lines ...
return m, m.executeCtxCommand([]string{contextName})
}
// Special handling for namespaces view
if m.currentGVR.Resource == "namespaces" {
// ... 12 lines ...
return m, m.executeNsCommand([]string{namespaceName})
}
if m.currentGVR.Resource == k8s.ResourceLogs {
return m, nil
}
// ... 25 more lines of generic drill-down ...
Every view is a conditional in a flat dispatch. There are 20+ occurrences of m.currentGVR.Resource == used as a type discriminator in this single file. Not types. String comparisons. Every new view means touching every handler.
What to do instead: Put this in your CLAUDE.md:
# State Ownership Rules
- NEVER add fields to the App/Model struct for view-specific state.
- Each view is a separate struct implementing the View trait/interface.
- Each view declares its own key bindings. The app dispatches keys to the active view.
- If you need to add a keybinding, add it to the relevant view's keymap, not a global one.
- Adding a view means adding a file. If your change requires modifying existing views, stop and ask.
The AI will always take the shortest path ("add another if-branch"). Your job is to make the shortest path also the correct path by putting guardrails in the file it reads on every invocation.
Tenet 3: Velocity illusion widens your scope.
This one's psychological, not technical, and I think it's the most dangerous.
When I started k10s, I wanted a GPU-focused tool. For people running training clusters. A niche audience that I'm part of. But vibe-coding made everything feel cheap. "Oh I can add pods view in one session? Let me add deployments too. And services. And a full command palette. And mouse support. And contexts. And namespaces."
Suddenly I was building k9s. A general-purpose Kubernetes TUI. For everyone. Because the AI made it feel like each feature was free.
It wasn't free. Each feature was another branch in the god object. Here's the keybinding struct:
type keyMap struct {
Up, Down, Left, Right key.Binding
GotoTop, GotoBottom key.Binding
AllNS, DefaultNS key.Binding
Enter, Back key.Binding
Command, Quit key.Binding
Fullscreen key.Binding // log view
Autoscroll key.Binding // log view (also shell in pods!)
ToggleTime key.Binding // log view
WrapText key.Binding // log + describe view
CopyLogs key.Binding // log view
ToggleLineNums key.Binding // describe view
Describe key.Binding // resource views
YamlView key.Binding // resource views
Edit key.Binding // resource views
Shell key.Binding // pods (CONFLICTS with Autoscroll!)
FilterLogs key.Binding // log view
FleetTabNext key.Binding // fleet view only
FleetTabPrev key.Binding // fleet view only
}
One flat keymap for all views. Comments in parens show which view each binding applies to. Autoscroll and Shell are both s. This "works" because the dispatch checks m.currentGVR.Resource before acting. But it means you can't reason about keybindings locally. You have to trace through the entire 500-line Update function to know what a key does.
The complexity was accumulating invisibly while the velocity metric said "you're shipping!"
What to do instead: Write a vision doc that explicitly says who you're NOT building for, and put the scope boundary in your CLAUDE.md:
# Scope (do NOT expand beyond this)
k10s is for GPU cluster operators. Not all Kubernetes users.
Supported views: fleet, node-detail, gpu-detail, workload. That's it.
Do NOT add generic resource views (pods, deployments, services).
Do NOT add features that duplicate k9s functionality.
If a feature request doesn't serve someone running GPU training jobs, reject it.
Vibe-coding makes you feel like you have infinite implementation budget. You don't. You have infinite LINE budget (the AI will generate as much code as you want). But you have the same finite complexity budget as always. The architecture can only support so many features before it buckles, regardless of how fast you wrote them. The CLAUDE.md scope section is you saying no in advance, before the velocity high convinces you to say yes.
Tenet 4: Positional data is a time bomb.
Every resource in k10s was fetched from the Kubernetes API and immediately flattened:
type OrderedResourceFields []string
Column identity was purely positional. Here's the sort function for the fleet view. Look at the index access:
func sortFilteredResources(rows []k8s.OrderedResourceFields, times []time.Time, tab FleetTab) {
sort.SliceStable(indices, func(a, b int) bool {
ra := rows[indices[a]]
rb := rows[indices[b]]
switch tab {
case FleetTabGPU:
// Sort by Alloc column (index 3) ascending
allocA, allocB := "", ""
if len(ra) > 3 {
allocA = ra[3]
}
if len(rb) > 3 {
allocB = rb[3]
}
return allocA < allocB
case FleetTabCPU:
// Sort by Name column (index 0) ascending
nameA, nameB := "", ""
if len(ra) > 0 {
nameA = ra[0]
}
if len(rb) > 0 {
nameB = rb[0]
}
return nameA < nameB
case FleetTabAll:
// GPU nodes first, then CPU nodes.
// Within GPU: sort by Alloc (index 3).
// Within CPU: sort by Name (index 0).
computeA, computeB := "", ""
if len(ra) > 2 {
computeA = ra[2]
}
if len(rb) > 2 {
computeB = rb[2]
}
aIsGPU := strings.HasPrefix(computeA, "gpu")
bIsGPU := strings.HasPrefix(computeB, "gpu")
// ...
}
})
}
ra[3] is Alloc. ra[2] is Compute. ra[0] is Name. These are magic numbers. The only thing connecting index 3 to "Alloc" is a comment and the column order defined in resource.views.json:
{
"nodes": {
"fields": [
{ "name": "Name", "weight": 0.28 },
{ "name": "Instance", "weight": 0.15 },
{ "name": "Compute", "weight": 0.12 },
{ "name": "Alloc", "weight": 0.12 },
...
]
}
}
Add a column between Instance and Compute? Every sort, every conditional render, every place that says ra[2] or ra[3] is now silently wrong. The compiler can't help you because it's all []string. And the JSON config can't express sort behavior, conditional rendering, or custom drill targets, so those live in Go code that hardcodes the positional assumptions from the JSON.
AI generates this pattern because it's the shortest path from "fetch data" to "render table." A []string satisfies any table widget immediately. Typed structs require more ceremony upfront. So the AI picks the fast path, and six months later you're debugging why sort puts "Name" values in the "Alloc" column.
What to do instead: Put this directive in your CLAUDE.md:
# Data Representation
- NEVER flatten structured data into []string, Vec<String>, or positional arrays.
- All data flows as typed structs (FleetNode, PodInfo, etc.) until the render() call.
- Column identity comes from struct field names, not array indices.
- Sort functions operate on typed fields, never on positional access like row[3].
- The ONLY place strings are created for display is inside render()/view() functions.
Then your typed struct makes impossible states impossible [2]:
struct FleetNode {
name: String,
instance_type: String,
compute_class: ComputeClass,
alloc: GpuAlloc,
}
You can't sort by the wrong column when columns are named fields. You can't accidentally compare Alloc strings as names. The compiler enforces this for you. AI will always pick Vec<String> because it satisfies the prompt faster. Your CLAUDE.md makes the typed path the path of least resistance.
Tenet 5: AI doesn't own state transitions.
The Bubble Tea architecture has a beautiful idea: Update() is the only place state mutates, driven by messages. But k10s violated this. The updateTableMsg handler spawned a closure that mutated Model fields from inside a goroutine:
case updateTableMsg:
return m, func() tea.Msg {
// block on someone sending the update message.
<-m.updateTableChan
// Preserve cursor position across column/row updates so that
// background refreshes don't reset the user's selection.
savedCursor := max(m.table.Cursor(), 0)
// run the necessary table view update calls.
m.updateColumns(m.viewWidth)
m.updateTableData()
// Restore cursor, clamped to valid range.
rowCount := len(m.table.Rows())
if rowCount > 0 {
if savedCursor >= rowCount {
savedCursor = rowCount - 1
}
m.table.SetCursor(savedCursor)
}
return updateTableMsg{}
}
This returned function (a tea.Cmd) is executed by Bubble Tea in a separate goroutine. It calls m.updateColumns(m.viewWidth) and m.updateTableData() which read and write m.resources, m.table, m.viewWidth. Meanwhile, View() is called on the main goroutine reading the same fields. There's no lock. No mutex. The channel <-m.updateTableChan blocks the goroutine until someone sends an update signal, but nothing prevents View() from reading half-written state.
This is a textbook data race. It worked 99% of the time. Corrupted the display 1% of the time in ways that made me think I was going insane.
AI generates this because "just mutate it in the closure" is the shortest path to working code. Proper message passing (send a message back to Update(), let Update() apply the mutation atomically on the main loop) requires more types, more plumbing. The AI is optimizing for the prompt, not for correctness under concurrency.
What to do instead: All mutations to render-visible state happen on the main loop. Period. Background workers produce data. They send it as a message. The main loop receives the message and applies it. This is the one rule you cannot break in concurrent UI code.
// Background task:
tx.send(AppMsg::FleetData(nodes)).await;
// Main loop:
match msg {
AppMsg::FleetData(nodes) => {
self.fleet_view.update_nodes(nodes);
}
}
No shared mutable state. No data races. No "works 99% of the time." Put this in your CLAUDE.md:
# Concurrency Rules
- Background tasks (watchers, scrapers, API calls) NEVER mutate UI state directly.
- Background tasks send results through a channel as typed messages.
- Only the main event loop applies state mutations from received messages.
- render()/view() is a PURE function. No side effects. No I/O. No channel operations.
- If you need to update state from async work, define a new AppMsg variant.
If your AI doesn't generate this pattern by default, the directive makes it the only legal option.
IV
what I'm doing differently now
I'm rewriting k10s in Rust. Not because Rust is better but, because it's the language I can steer. I've written enough of it to feel when something's wrong before I can articulate why. That instinct is the one thing vibe-coding can't replace. The AI hands you plausible-looking code. You need a nose for when it's garbage.
The other change is simpler: I'm doing the design work myself, by hand, before any code gets written. Not a vague doc. Concrete interfaces, message types, ownership rules. The architecture decisions that the AI kept making wrong are now made in writing before the first prompt. Whether that's enough to keep the rewrite from collapsing under its own weight... I'll find out.
In the mean-time go star the TUI and show some love!
footnotes
[1] Bubble Tea is a TUI framework for Go based on The Elm Architecture. It's excellent. The architecture problems in k10s were mine, not Bubble Tea's.
[2] "Making impossible states impossible" is a phrase from Elm/Rust communities. The idea: design your types so that invalid states can't be constructed, rather than checking for invalid states at runtime.